
Analisis Sentimen Umpan Balik/Persepsi Pebelajar


10 min read

Selama menjelajah penelitian tentang Sentimen Analisis di Google Schoolar, tidak banyak penelitiaan yang bertopik tentang pendidikan. Jikapun ada, tidak membahas konsep pemanfaatan sentimen analisis, melainkan menguji performa model yang dikembangkan. Dilihat melalui kacamata Teknologi Pendidikan, kurang tepat rasanya untuk menuliskan penelitian yang membahas modelling arsitektur NLP.
Menjadi sebuah motivasi untuk mencoba analisis sentimen. Cara sederhana untuk mengetahui sentimen pebelajar. Data sentimen berasal dari umpan balik pebelajar setelah proses pembelajaran. Alasan meneliti data umpan balik pun cukup sederhana, yaitu karena tidak banyak dilakukan dalam sudut pandang pemanfaatan atau Proof-of-Concept (PoC). Penelitian ini relevan dengan definisi teknologi pendidikan, baik lingkup memfasilitasi pembelajaran atau meningkatkan performa.
Salah satu penelitian yang menarik ialah milik dosen saya dengan judul "Digital News Transformation on Education in the Most Affected Country by COVID-19 Using the Topic Modeling and Sentiment Analysis doi:10.1109/ICET56879.2022.9990686". Penelitian beliau terfokus pada interpretasi hasil analisis. Berbeda dengan penelitian lainnya yang fokus pada akurasi model.
Metode
Metode yang digunakan pada studi kasus ini cukup sederhana, sekadar melakukan pengumpulan data, pembersihan, uji sentimen, dan interpretasi. Saya mencoba untuk menghindari langkah - langkah kompleks karena kebutuhan saat ini hanyalah sebagai proof of concept. Prosedur dari penelitian ini dapat dilihat dari diagaram alir sebagai berikut.
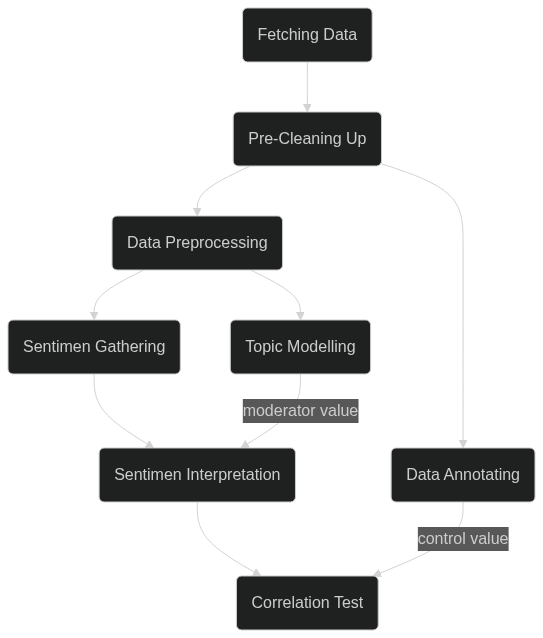
Untuk lebih jelasnya, berikut penjelasan dsasar dari setiap tahapan yang akan dilakukan,
Fetching data, melakukan pengambilan data dari pusat data.
Cleaning up, membersihkan data dari galat sistem dan karakter non alfabet.
Data Preprocessing, membersihkan data berdasarkan teknik NLP.
Data Annotating yaitu proses pelabelan data yang dilakukan oleh manusia sebagai data kontrol.
Topic modelling, melakukan analisi topic berdasarkan algoritma LDA.
Sentiment Gathering, melakukan pengambilan sentimen melalui API NLP Google Cloud.
Sentimen Interpretation, melakukan interpretasi dari proses sentimen gathering dan melakukan uji korelasi antara hasil sentimen dengan topic modelling.
Correlation test, proses untuk membandingkan hasil proses interpretasi yang telah dilakukan dengan hasil annotasi data yang dilakukan oleh manusia.
Seluruh proses ini memanfaatkan bahasa pemrograman python v3.11 didukung berbagai library dan package.
Hasil
Proses Fetching Data
Proses fetching dilakukan dengan melakukan mengunduh data tanpa melakukan pengurangan jumlah data. Terdapat pemrosesan yang dilakukan yaitu (1) melakukan normalisasi pada kolom created_at menjadi format yyyy-mm-dd , (2) penyensoran user_id ,(3) normalisasi kolom topic_id menjadi nominal progress pebelajar.
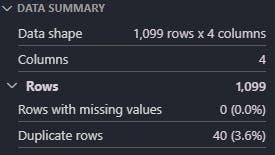
Total data yang diunduh dari database berjumlah 1099 baris yang terdiri dari empat kolom. Kolom created_at mendeskripsikan kapan survey itu dikirimkan, message yaitu pesan/survey yang dituliskan oleh pebelajar, user_id pebelajar yang mengirimkan pesan tersebut, dan topic_id yaitu topik pembelajaran yang sedang disampaikan.
Hasil data summary, 94% data pada baris message memiliki nilai yang berbeda. Setelah dianalisa dengan singkat, terdapat baris yang memiliki kesamaan pesan. Kondisi ini tidaklah ideal untul dilakukan analisis, maka perlu dibuang pada tahap selanjutnya.

Gambaran umum dari data yang telah diunduh dari database sebagai berikut:
| Description | Value |
| Row Count | 1099 Rows |
message distinction rate | 94% (~1036 value) |
created_at distinction rate | 5% (54 value) |
user_id distinction rate | 12% (127 value) |
Pre Cleanup
Setelah data diunduh, data akan dibersihkan dari residu yang dapat menggagu proses analisis sentimen. Bentuk - bentuk residu yang dihilangkan pada tahapan ini diantaranya,
Noise Removal, menghapus karakter non alfabet, seperti tanda baca, emoji dan karakter lainnya.
Casefolding, mengubah seluruh huruf kapital menjadi huruh kecil.
Repeated Character, mengubah huruf yang muncul secara berulang - ulang dalam satu kata, contoh "Kenapaa Sihhh" menjadi "kenapa sih".
PII Obfuscation, mengubah nama - nama orang menjadi kata ganti profesi, seperti nama asli dosen atau asisten .
Mengubah kata gaul atau slang menjadi kata formal.
Stopword Removal, menghapus kata stopwords pada pesan survey.
Remove whitespace, menghapus spasi ganda.
Menghapus pesan dengan jumlah karakter di bawah 70 karakter, hal ini digunakan sebagai kriteria umum dari survey yang layak untuk dilanjutkan proses analisis sentimen.
Duplicate Deletion, menghapus konten pesan yang isinya sama, sehingga meningkatkan distinction rate dataset sehingga seluruh pesan dalam isi dataset bersifat unik.
Setelah proses cleanup dilakukan, jumlah baris berkurang menjadi 629 baris. Tidak ada perubahan jumlah kolom, melainkan menambah kolom processed_message dengan value dari proses cleanup.
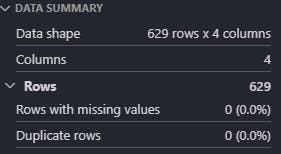
Distinction rate meningkat menjadi 100%, hal ini menandakan bahwa seluruh pesan duplikat telah dihilangkan, sehingga setiap baris bersifat unik.

Hal menarik akibat proses cleanup ialah terjadi penuruan agregasi berdasarkan topic_id, dapat diartikan bahwa jumlah survey pada sebuah topik pembelajaran menurun jumlahnya berdasarkan topik pembelajaran, namun tren penurunan yang terjadi cukup stabil. Nilai terendah terdapat pada topik pembelajaran ke-8 dan nilai tertinggi berada pada topik pembelajaran ke-0.
Data Pre-Processing
Pada tahap ini, dilakukan proses stemming terhadap hasil survei yang telah dilakukan pembersihan. Stemming adalah proses untuk mengubah sebuah kata menjadi kata dasar. Contohnya seperti aku memakan buah apel itu menggunakan sendok menjadi aku makan buah apel itu guna sendok. Proses stemming dilakukan karena teks menjadi lebih sederhana dan tidak kompleks bagi model NLP dalam melakukan pelabelan sentimen.
| Metric | Stemmed | Non-stemmed |
| Word count | 10575 | 10574 |
| Char count | 68326 | 78969 |
| Word reduction | -0.0% | -0.0% |
| Char reduction | 13.5% | 13.5% |
| Average word length | 6.6 | 7.6 |
| Unique words | 629 | 629 |
| Unique word percentage | 5.9% | 5.9% |
Dari hasil stemming yang telah dilakukan, terdapat penurunan yang cukup signifikan terhadap jumlah karakter. Terjadi penurunan sebanyak 10.643 karakter, jika dipersentasekan terhadap jumlah karakter non-stemmed , terjadi pengurangan sebesar ~10%. Penurunan ini signifikan serta diharapkan dapat meningkatkan performa model NLP yang akan digunakan dalam proses analisis sentimen.
Hasil survei yang telah diproses akan dilanjutkan pada proses sentiment gathering. Sentimen gathering akan menggunakan dua (2) model NLP, yaitu Google Cloud Natural Language dan IndoBERT.
Sentimen Gathering - IndoBERT Model
Sentimen gathering menggunakan IndoBERT mudah untuk dilakukan. Secara bawaan, IndoBERT memberikan output yang cukup sederhana, yaitu sentimen label dan sentiment_score. Sentimen label merupakan tendensi sentimen, output yang diberikan ialah positive, negative, dan neutral. Sentiment Score merupakan kekuatan sentimen yang diberikan, skala skor yang diberikan dari rentang 0 hingga 1. Contoh dari output yang dihasilkan dapat dilihat di tabel di bawah ini:
| message | sentiment_label | sentiment_score |
| cerita rasa tugas dimensi pesimis tugas sanggup menang sadar tugas mudah matkul per tokopedia | negative | 0.911978662 |
| ajar produk 3d blender ajar tools kembang produk tau tools grab belah produk boolean lainlain | neutral | 0.7909024358 |
| modul ajar bagus ajar modul simpel keren modul mudah akses | positive | 0.9884135127 |
| bab labelling materi tutorial dapat mudah paham terap produk selesai | neutral | 0.515247345 |
Proses penafsiran output IndoBERT cukup sederhana. Sebuah sentimen dikatakan memiliki nilai emosional yang kuat ketika memiliki score sentimen yang mendekati 1 dan dikatakan rendah jika mendekati 0. Bagaimana dengan netral? Kasus netral ini cukup kompleks karena terdapat satu sentimen yang sulit untuk terdeteksi yaitu mixed. Secara sistem, IndoBERT tidak menghasilkan output sentimen mixed, sehingga sentimen score pada neutral masih belum secara jelas dapat terdefinisikan.
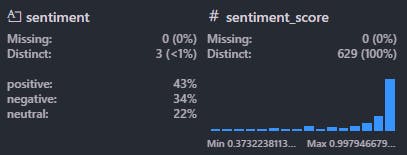
Secara umum, sentiment gathering menggunakan IndoBERT menghasilkan nilai positive sebanyak 43%, negative 34% dan sisanya netral. Sedangkan pada sentimen score, memiliki rata - rata 0.85. Dapat disimpulkan bahwasanya, menurut IndoBERT, kekuatan emosional dari sentimen pada hasil survei cenderung kuat dan ekspresif baik dalam mengutarakan perasaan positif maupun negatif.
Sentimen Gathering - Google NLP API
Pada proses sentimen gathering menggunakan google NLP, terdapat karakteristik output yang unik. Google NLP tidak memberikan ketetapan terhadap hasil sentimen, melainkan memberikan skor sentimen seperti halnya indoBERT. Skor sentimen yang diberikan memiliki rentang dari -1 hingga 1. Selain itu, terdaapat nilai tambahan dengan sebutan magnitude score. Magnitude score memiliki arti yang sama seperti sentimen score pada IndoBERT, yaitu kekuatan sentimen.
Dalam dokumentasi yang diberikan, terdapat panduan interpretasi secara sederhana:
Sentiment Sample Values Clearly Positive* "score": 0.8,"magnitude": 3.0Clearly Negative* "score": -0.6,"magnitude": 4.0Neutral "score": 0.1,"magnitude": 0.0Mixed "score": 0.0,"magnitude": 4.0
Dari pedoman tersebut, interpretasi dilakukan dengan cara conditional branching terhadap score sentimen. Jika nilai score diatas 0, maka sentiment dinyatakan positif dan sebaliknya. Berikut hasil sentimen gathering yang telah dilakukan:
| message | sentimen_score | sentimen_magnitude | sentiment |
| cerita rasa tugas dimensi pesimis tugas sanggup menang sadar tugas mudah matkul per tokopedia | -0.3030000031 | 0.4410000145 | negative |
| alam materi senang bangga bikin aplikasi blender hehehe baik sesuai | 0.9380000234 | 0.9850000143 | positive |
| alam materi tegang pilih juduk timbang babbab depan kenal buka aplikasi blender pilih judul berat depan | -0.0120000001 | 0.0520000011 | negative |
| daki gunung lewat lembah menggerjakan bab sampai hujung jalan validasi produk | 0 | 0.1220000014 | negative |
| kain ucap teimakasih mohon maaf sumpa iki tugas tereffort sakumur umur terjang hujan gerimis beldekan barang hahahaha | 0.001 | 0.7490000129 | positive |
Untuk melakukan labelisasi neutral, digunakan skala tiga kategori menggunakan score sentiment. Untuk memudahkan proses labelisasi, digunakan fungsi kategorisasi sebagai berikut dengan kondisi diatas 0.4 merupakan positif, dibawah -0.4 merupakan negatif, sisanya ialah neutral.
def label_sentiment(score):
if pd.isnull(score):
return score
elif score > 0.4:
return 1
elif score < -0.4:
return -1
else:
return 0
Dari proses kategorisasi yang telah dilakukan, didapatkan gambaran umum hasil sebagai berikut:
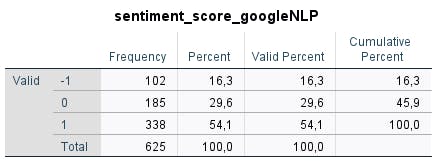
Model Performance Analysis
Analisis performa model merupakan tahapan membandingkan hasil sentimen gathering dari kedua model NLP. Pada tahapan ini, dilakukan perbandingan melalui confusion matrix secara sederhana. Berikut ialah hasil dari proses analisis model yang telah dilakukan.
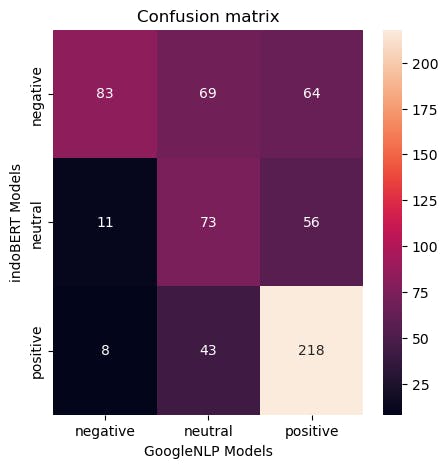
Pada hasil confusion matrix hasil sentiment labelling yang dilakukan, model NLP Google dan IndoBERT memiliki konsistensi yang tinggi pada label positif. Hasil yang sama pun ditemukan pada konsistensi labelling negatif. Terdapat hasil yang menarik dari kedua model ini, yaitu tingginya ketidakselarasan label positif (googleNLP) dan label negatif (indoBERT). Perdaan labelling ini dapat diartikan bahwasanya kedua model memiliki karakteristik dalam menandai sentimen. Dari hasil berikut, dibutuhkan hasil analisis akurasi dan konsistensi dari kedua model untuk mengetahui keandalannya untuk diimplementasikan dalam proses evaluasi pembelajaran.
| # | Metric | Score |
| 0 | Global Accuracy | 80.7% |
| 1 | Precision | 77.3% |
| 2 | Recall | 96.5% |
| 3 | F1 score | 85.8% |
| 4 | MCC | 60.2% |
| # | Error Rate | Subset Accuracy | Precision |
| 0 | 40.2% | 59.8% | 61.8% |
| # | precision | recall | f1-score | support |
| negative | 81.4% | 38.4% | 52.2% | 216 |
| neutral | 39.5% | 52.1% | 44.9% | 140 |
| positive | 64.5% | 81.0% | 71.8% | 269 |
| accuracy | 59.8% | 59.8% | 59.8% | 0.5984 |
| macro avg | 61.8% | 57.2% | 56.3% | 625 |
| weighted avg | 64.7% | 59.8% | 59.0% | 625 |
Untuk analisis akurasi dan konsistensi, digunakan IndoBERT model sebagai baseline atau standar sedangkan GoogleNLP sebagai predicted value. Dari hasil akurasi secara keseluruhan, kedua model tersebut mendapatkan akurasi 80%, dan tingkat presisi setinggi 70%.
Jika dilihat dari akurasi per kategori labelling, label positif mendapatkan tingkat recall yang sangat tinggi, yang dapat diartikan model GoogleNLP mampu melabeli data sentimen positif dengan karakteristik yang sama dengan model IndoBERT. Sedangkan tingkat recall paling rendah yaitu pada label negatif namun tingkat presisi yang didapatkan paling tinggi, dapat diartikan GoogleNLP mampu menandai data sentimen positif dengan karakteristik nada atau tone yang sama namun tidak seragam dengan model IndoBERT.
Kesimpulan
Dari hasil yang telah didapatkan, secara umum, analisis sentimen dapat dimanfaatkan untuk mengetahui persepsi pebelajar secara umum terhadap pembelajaran. Analisis sentimen tidak dapat memberikan informasi yang komprehensif terhadap persepsi proses pembelajaran. Meskipun demikian, hasil sentimen gathering dapat dijadikan acuan mendasar bagi para pembelajar untuk mengetahui sentimen pebelajara dalam kerangka yang lebih asbtrak. Diperlukan analisis mendalam terhadap hasil sentimen yang dilakukan oleh model NLP untuk mendapatkan pandangan yang lebih dalam terhadap persepsi pembelajaran.
Analisis persepsi dapat dilakukan baik dengan googleNLP maupun indoBERT. Tingkat akurasi dan presisi yang cukup tinggi menjadikan kedua model tersebut dikatakan reliabel dan andal dalam memberikan label sentimen dari sebuah data hasil pembelajaran.
Saran untuk case study berikutnya ialah ketersediaan data yang telah dianotasi oleh manusia, khususnya pembelajar sebagai data referensi. Selain itu, pemeringkatan kata dengan opini negatif maupun positif dapat dilakukan secara sederhana untuk mengetahui point of pain atau point of joy dari para pebelajar.